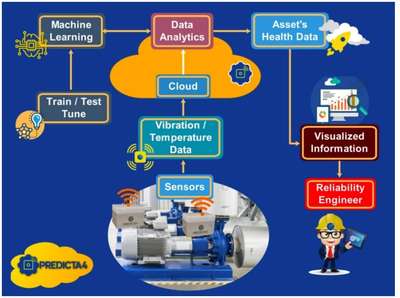
在用户规模指数级增长、数据形态日益复杂的时代,小米作为全球领先的智能硬件与互联网服务公司,其业务生态产生了海量、多维、实时与离线并存的异构数据。为高效、稳定、智能地挖掘数据价值,赋能业务决策与用户体验提升,小米构建了名为“数据工场”的集中化、平台化数据处理体系。其技术架构与数据处理服务的设计,核心围绕高扩展、高可靠、低成本、易用性四大原则展开。
一、 分层解耦的技术架构
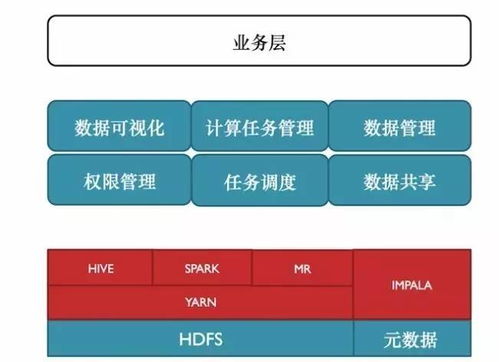
小米数据工场采用典型的分层架构设计,自下而上分为:
- 统一数据存储层:
- 核心组件:基于HDFS、对象存储、Kafka等构建混合存储池。对离线数据、实时流数据、非结构化数据等进行统一纳管。
- 关键设计:实行数据湖仓一体策略。原始数据以低成本方式入湖,保存全量细节;通过分层建模(ODS->DWD->DWS->ADS),构建主题清晰、易于分析的数据仓库,兼顾灵活性与性能。
- 弹性计算与调度层:
- 计算引擎:根据场景选用不同引擎。离线批量处理采用Spark、MapReduce;实时流处理采用Flink;交互式查询采用Presto/Trino;机器学习任务则集成TensorFlow、PyTorch等框架。
- 资源调度:基于YARN或Kubernetes实现统一的资源管理与调度,支持计算任务的弹性伸缩,有效应对业务高峰,并提升集群资源利用率。
- 工作流调度:使用Apache Airflow或自研调度系统,以DAG(有向无环图)形式编排复杂的数据处理管道,确保任务依赖清晰、执行有序、故障可回溯。
- 数据开发与管理层:
- 一体化开发平台:提供Web化的IDE,支持SQL、Python、Scala等多种语言进行数据开发,内置任务调试、版本管理、血缘分析等功能,降低数据开发门槛。
- 元数据与数据治理:构建统一的元数据中心,自动采集数据表、字段、血缘、生命周期等信息。通过数据地图、数据质量监控(如完整性、准确性校验)、数据安全分级与脱敏,实现数据的可知、可信、可控。
- 统一服务与API层:
- 将处理后的数据,通过统一的数据服务总线,以API、消息、数据文件等多种形式,安全、高效地分发给下游的报表系统、推荐系统、风控系统等业务应用。
二、 核心数据处理服务
基于上述架构,小米数据工场提供了一系列关键的数据处理服务:
- 实时数据流处理服务:
- 场景:用户行为实时追踪、APP实时监控、实时风控、实时推荐等。
- 实现:通过Flink消费Kafka中的实时数据流,进行窗口聚合、复杂事件处理、实时特征计算等,结果写入OLAP引擎(如ClickHouse、Druid)或在线数据库,供业务方低延迟查询。
- 离线大数据处理服务:
- 场景:海量日志分析、用户画像构建、经营分析报表、模型训练数据准备等。
- 实现:利用Spark进行大规模ETL(抽取、转换、加载),执行复杂的多表关联、聚合运算,按主题域构建数据模型,产出T+1或小时级的分析数据。
- 数据集成与同步服务:
- 功能:支持从MySQL、PostgreSQL等OLTP数据库,通过CDC(变更数据捕获)技术实时同步数据至数据湖;也支持将处理结果同步回业务数据库或各类数据存储。工具如DataX、Canal、Debezium被广泛集成。
- 机器学习平台服务:
- 一体化流程:在数据工场内集成特征工程、模型训练、在线推理服务。数据科学家可以直接使用平台处理好的特征数据,通过Notebook或拖拽式界面进行模型开发,并一键部署为在线服务,形成从数据到智能的闭环。
- 数据质量与运维服务:
- 全链路监控:对数据任务的计算耗时、资源消耗、数据产出时效、数据质量指标进行全方位监控与告警。
- 智能运维:基于历史数据预测任务运行时间,自动优化资源分配;对失败任务进行根因分析与智能重试,保障数据产出的SLA。
三、 面向未来的演进方向
面对持续增长的数据挑战,小米数据工场正朝着更智能、更自治的方向演进:
- 智能化:引入AI技术优化自身,如通过强化学习动态调整调度策略,利用算法自动优化数据分布与存储格式,实现基于成本的自动化优化。
- Serverless化:向用户提供更抽象的数据处理服务,屏蔽底层基础设施的复杂性,让开发者更专注于业务逻辑。
- 实时化深化:进一步融合流批处理能力,推广实时数仓和实时特征平台,满足业务对数据时效性日益苛刻的需求。
小米数据工场通过分层解耦、引擎多元、平台化服务化的架构设计,构建了一个能够支撑亿级用户、PB级数据、多业务场景的稳健数据处理体系。它不仅是大数据技术的集合,更是将数据作为核心生产要素,系统性赋能小米全生态业务创新的重要基础设施。