在智能运维(AIOps)场景下,大数据处理是实现故障预测、异常检测和根因分析等核心能力的基础。在分布式计算框架(如Spark、Flink)中处理海量运维数据时,数据倾斜(Data Skew)是一个常见且棘手的问题。数据倾斜指的是在分布式处理过程中,数据或计算负载在多个任务(Task)或分区(Partition)间分配极度不均,导致少数任务负载过重,成为整个作业的性能瓶颈,严重时甚至引发内存溢出(OOM)和作业失败。
数据倾斜通常表现为:
- 个别任务执行时间异常漫长,远超其他任务。
- 大部分任务很快完成,但整个作业需要等待少数几个“拖后腿”的任务。
- 在Spark等框架的监控UI中,可以观察到Stage内任务处理的数据量或记录数存在巨大差异。
数据倾斜的成因
在运维数据处理中,倾斜通常源于数据本身的分布特性:
- 键值分布不均:在进行
join、groupBy、reduceByKey等聚合操作时,某些键(Key)对应的数据量异常庞大。例如,在按“主机名”或“服务ID”分组统计错误日志时,某个故障服务的日志量可能占总量的大部分。 - 数据源分区不均:源头数据(如Kafka topic的partition、HDFS文件块)本身就分布不均匀。
- 业务数据热点:如全公司的网络流量都经过某几个核心交换机,或者某几个关键业务模块产生的指标数据量远超其他模块。
针对性的解决方案
解决数据倾斜需要从数据、业务和计算框架等多个层面综合施策。
- 预处理与过滤:
- 热点数据分离:识别并分离出导致倾斜的“热点Key”。可以对这些热点数据(如某个核心服务的日志)进行单独处理,例如用一个独立的作业先行聚合,再与正常数据的结果进行合并。
- 无效数据过滤:在业务允许的前提下,过滤掉一些无意义的、量大的中间数据或调试日志,从源头减少数据量。
- 调整任务并行度与分区策略:
- 提高Shuffle并行度:通过设置
spark.sql.shuffle.partitions(Spark SQL)或reduceByKey的numPartitions参数,增加Shuffle后的分区数量,让负载更分散。但这对于存在极端热点Key的情况效果有限。
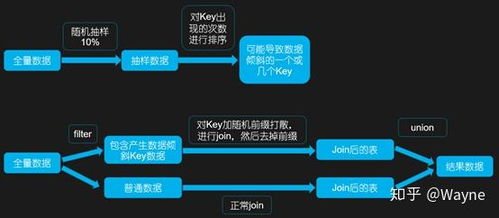
- 自定义分区器:实现自定义的Partitioner,将热点Key打散到多个不同的分区中,避免单个分区承载过多数据。例如,可以将原始Key加上随机前缀(如
hotkey<em>1,hotkey</em>2),先进行聚合,最后再去掉前缀进行二次聚合。
- 优化Shuffle操作:
- 使用Map端聚合:在Shuffle前,尽可能使用
combineByKey、reduceByKey等带有预聚合(Combine)功能的算子,减少Shuffle传输的数据量。
- 将Reduce侧Join转为Map侧Join:当一张表较小时,使用
broadcast(广播变量)将其分发到所有计算节点,将Reduce Join转换为Map端的本地查找,彻底避免由大表关联引起的Shuffle倾斜。这是解决Join倾斜最有效的手段之一。
- 倾斜Join优化:对于无法广播的大表Join,可采用“拆分倾斜Key”的策略。识别出大表中的倾斜Key,将其单独取出,与另一张小表(或该Key对应的另一张表的分片)进行广播Join,而将剩余的正常数据进行普通的Shuffle Join,最后合并结果。Spark 3.0+ 的AQE(自适应查询执行)可以自动检测并在一定条件下处理倾斜Join。
- 利用框架高级特性:
- 启用Spark AQE:在Spark 3.0及以上版本,启用自适应查询执行(
spark.sql.adaptive.enabled=true),AQE可以动态合并小的分区、拆分倾斜的分区,并在运行时优化Join策略,对缓解数据倾斜有显著效果。
- 增加资源与调整配置:为可能承载热点数据的分区任务分配更多资源(如Executor内存)。调整
spark.sql.adaptive.skewJoin.skewedPartitionFactor等参数,让框架更敏感地识别倾斜。
- 业务与数据模型优化:
- 设计更均匀的Key:在数据采集或ETL阶段,考虑设计更分散的聚合维度。例如,将“分钟级时间戳”作为Key可能造成每分钟一个热点,可考虑与“机器ID”等组合成复合Key。
- 数据采样与预分析:在处理前对数据进行采样分析,了解数据分布,提前预判倾斜风险并制定策略。
****
处理智能运维场景下的数据倾斜问题,没有一劳永逸的银弹。关键在于监控中发现倾斜迹象,并结合具体业务逻辑分析成因。解决方案通常是从最简单的增加并行度开始,逐步升级到分离热点、优化Join、利用AQE等高级策略。一个优秀的智能运维数据处理服务,应当将数据倾斜的预防、检测和缓解机制内嵌到其处理流水线中,通过动态配置和自动化策略,保障大规模运维数据分析任务的稳定与高效执行。